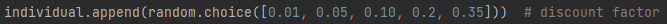In this post I will be concluding my findings that I have obtained and what I have learned throughout the development of my AI.
DQN
Due to not having lots of experience or knowledge about Machine Learning AI techniques, Deep Q Network (DQN) was an interesting approach to creating an AI that could playtest a video game environment. This is because it incorporated both Neural Networks and Q-learning which would allow for less chance of short term oscillations occurring when monitoring a moving target (N. Yannakakis and Togelius 2018).
After using Stable Baselines3’s DQN class, I had found it very useful when trying to get it to work with OpenAI Gym’s Atari environments since it was designed to work with the type of AI environment library. In addition, it was quite easy to set up and get working, however the Atari environments must be the RAM versions to ensure they can work on standard computers. Adjusting the AI’s parameters was a simple process allowing for optimisation techniques to be easily implemented and used to ensure it could get good fix parameters. Additionally, the AI had parameters that I could adjust to manage when it should return evaluated results and when to stop training if it got a specific score.
One of the limitations with the DQN I found is that it struggles to learn how to work with random events. I discovered this after researching how DQN performs when playing a card game compared to another AI technique called Proximal Policy Optimization (PPO) as that DQN AI struggled to play against an agent using random actions (Barros et al. 2021). I found this to be true, as when training my AI in the Asterix (1983) environment (a game that has random features) it was able to learn patterns about the game but was not able to handle all them and would occasionally make simple mistakes.
Another problem I experienced with the DQN AI was that it kept taking advantage of a design flaw in the game causing it to stay still in one of the top corners of the environment. This was so that it would be efficient while getting a big score.
Genetic Algorithm and Optimisation
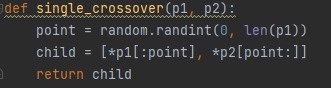
Using Genetic Algorithm (GA) as a parameter optimisation method has been a very useful technique as it has helped me pinpoint possible fixed parameters that I could use for the AI. This was achieved by using single crossover and mutation to generate new parameters based off the old ones and then test them to find the best one out of them all (Miller and Goldberg 1995). Additionally, by using this technique it saved me time from needing to adjust parameters by myself which would have been a much slower task.
Two problems I did have with using GAs was that it could take a while for the AI to create generations as well as train and test each one. However, this was likely due to the AI not having any training data or the reward threshold had not been set up to keep track of the most common reward being returned. The second problem I had faced, was the potential parameters could be quite limited and the results look quite similar to one another despite the mutations being applied. This may have been due to the range of mutations that could be applied or there not being enough example generations to use at the start of the system.
Looking into GA has introduced me to different techniques in AI as my knowledge base was quite limited. In addition, for future iterations of this AI and AI projects I will use it as a way to optimise finding the most useful fixed parameters.
Parameter adjustments
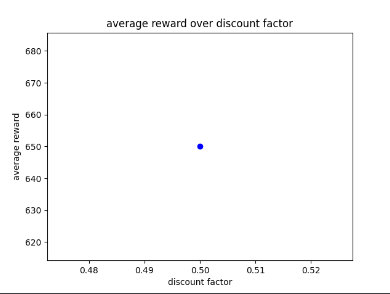
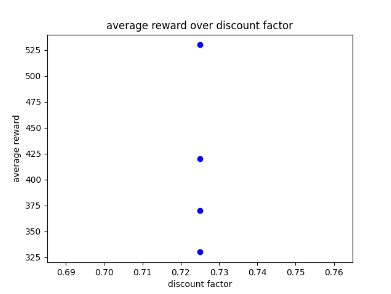
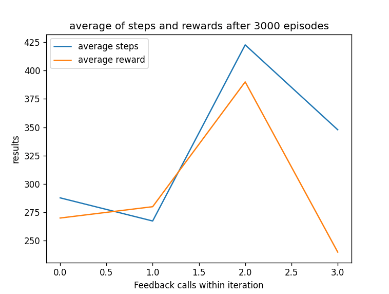
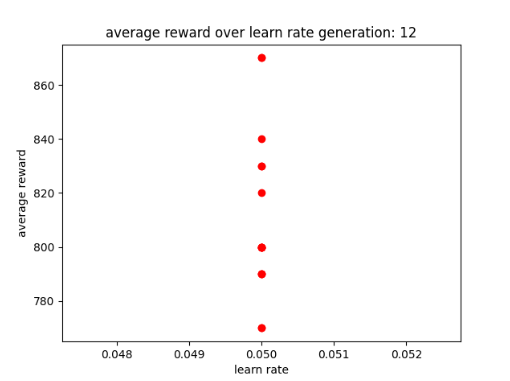
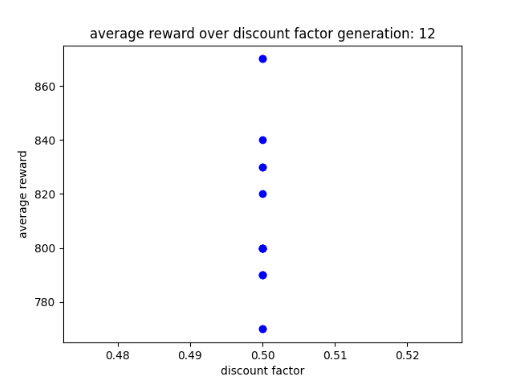
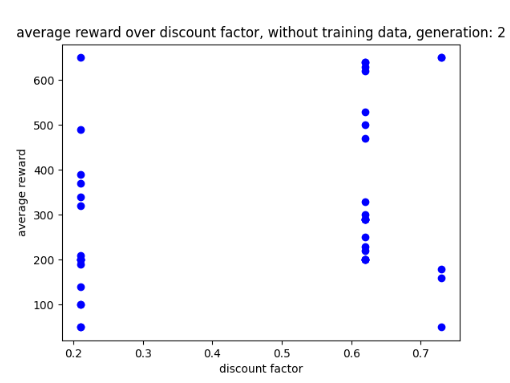
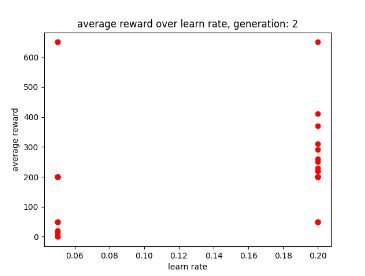
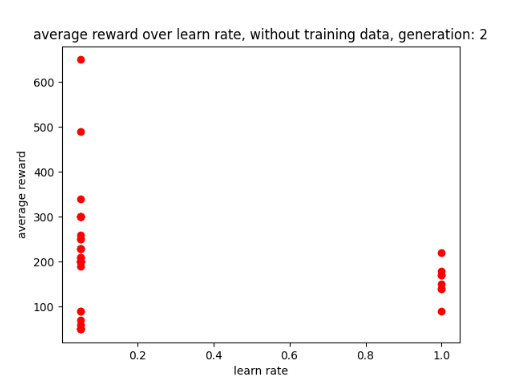
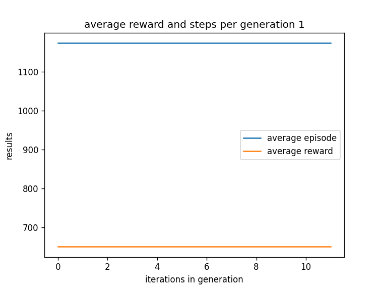
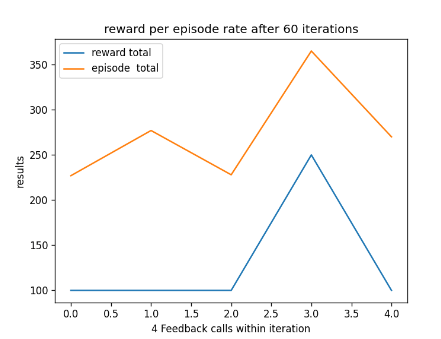
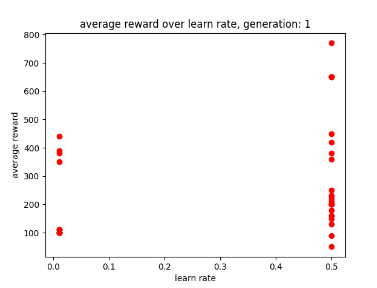
After using GA for 6 generations to find the best possible parameters I have learnt that the learn rate seems to work best between 0 and 0.5 and the discount factor works best between 0.5 and 1. After experimenting with fixed parameters with the constraints in mind, I found that the AI performs best when it has a step total of 10,000, a discount factor of 0.752 and a learn rate of 0.5. This is because it allowed the AI to achieve a score of 750 and learn patterns in the environment, however it was not able to maintain the score at a consistent rate. I chose 0.752 as the AI was achieving good scores that were between those numbers. Two examples of previous graphs are shown below. The AI was getting more consistent but low scores around a learn rate of 0.90, but having a learn rate of 0.75 resulted in the AI getting a higher score at a less consistent rate.

Step/reward monitoring techniques
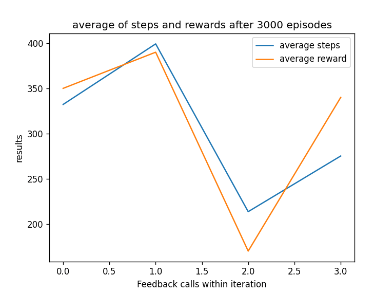
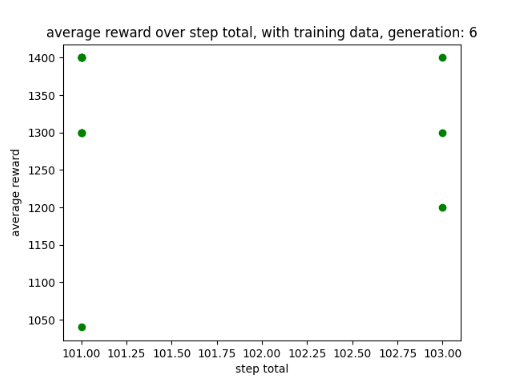
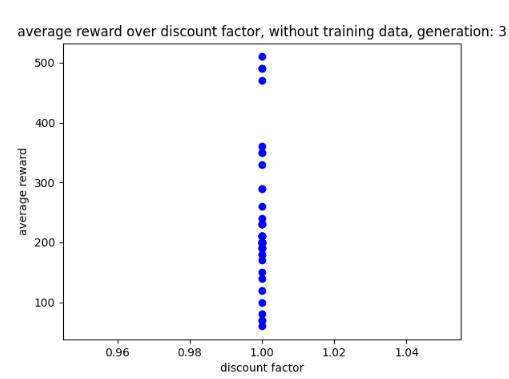
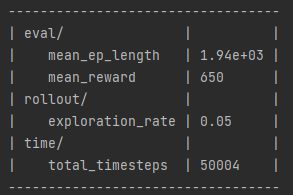
To improve how my AI saved its training data I introduced a custom feature intended to ensure that the AI does not override good training data with bad training data. This is because by observing my AI I noticed it slowly drops in progress near the end while still saving data. A graph of its progress drop is shown below in fig 3.

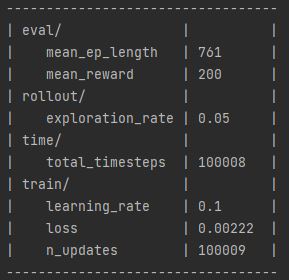
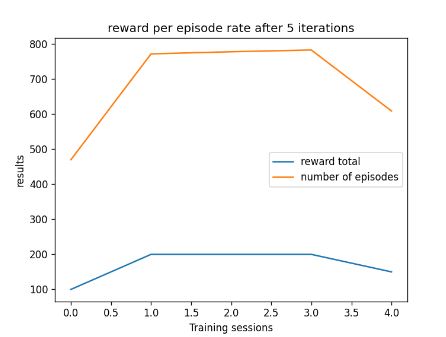
In addition, changing from monitoring steps to monitoring rewards has worked very well, allowing the AI to get a better score with a smaller number of steps. Using the reward technique has also prevented the AI from dropping in performance near the end of its training. An example can be found later in the post in fig 5.
Feature extraction
I decided to add a feature extraction technique as an extra layer of security to ensure the AI does not save training data if the AI has been standing still for too long. Looking at the results, the system did show some promise as the AI has performed better. However, it is a disappointment that OpenAI Gym’s environment reward function cannot be edited during training as I believe it would be more effective.
Feature extraction involves taking existing features in the AI and creating new ones in order to help the AI improve in its training (Ippolito 2019). While the system I had did not entirely do this due to scope and library limitations, it was monitoring how often the AI was standing still and preventing the AI from saving training data that stood still for too long. This was intended to encourage the AI to explore the environment more often.
Plotting graphs and CSV files
For my AI I had two different types of graphs to express the AI’s data and progress, line graphs and scatter graphs. In addition, the returned data was stored on csv files that could be used to plot the data on the graph.
Line graphs were useful to show off the progress of the AI over 4 evaluation callbacks but it does not work well when the data is not linear or with multiple parameters. I found it is very useful when showing the progress of an AI with fixed parameters.
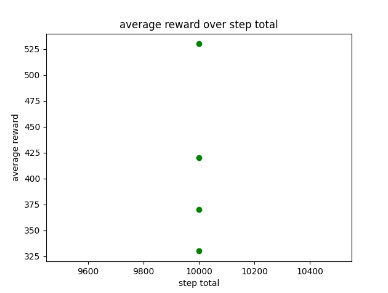
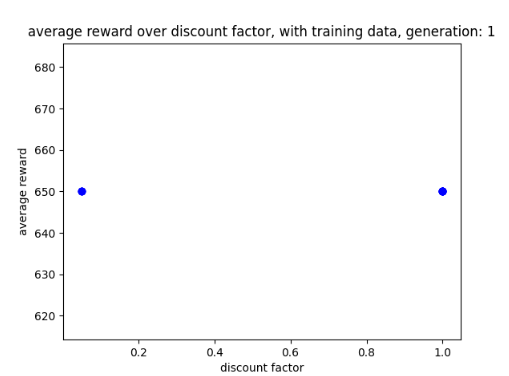
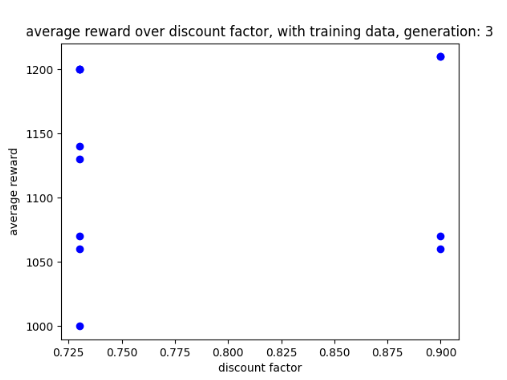
Scatter graphs were used for non linear data allowing for better representation of what parameters get what results. Though not entirely accurate, looking at the cluster of dots and looking at all the parameter graphs can give some guidance as to what parameters values work best. Below are two examples of the different scatter graphs.

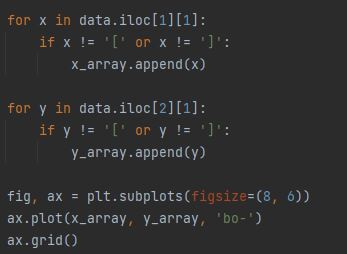
One problem that I did have with storing data on csv files, was that some data was stored on one cell of the csv file rather than each bit of data being stored on each cell in the table. Because of this I had to resort to building a filter that could break down the data and plot the data properly on a graph.
Further enquires
For future improvement, when it comes to parameter optimisation, I was thinking about having a system that would generate multiple AI and environments to see if this would allow for more effective training sessions and generate better parameters. Doing this multiple times with the same training data would enable me to see what results are returned. The one problem this could have would be computational requirements as having multiple AI running at the same time may put a strain on the computer’s RAM. (expand on multi agents running at the same time)
Upon further research AI techniques do exist to allow DQN AI to perform such tasks especially ones with randomness and low probability. For example, the system I found was experimented on to predict the stock market and was able to produce reasonable strategies for long term planning (Carta et al. 2021).
Reflection and Conclusion
Upon reflecting on my work, I have learned much throughout this development journey as I now understand how to build a DQN AI. In addition, it uses techniques like GA for improved parameter optimization as well as having systems to monitor and save data to ensure that the AI has the best training data.
While it is a shame that the AI cannot play Asterix (1983) properly or get a large score without overfitting, it is good to see that it can learn and play the game in general. In addition to that, the AI is able to improve itself using the training data and plot both line and scatter graphs to show the AI’s progress and which set of parameters provide the best results.
In conclusion, the AI is able to get a score between 200 to 750 while playing the game using the design flaw but also playing the game like a human would. In addition, the systems working alongside it have added it in collecting and plotting data for training purposes.
In future projects that require play testing I would be interested to see if I could incorporate my AI into them in order to try and get good feedback. However, this would require improvements and a library that would allow the AI to work with video game engines such as Unity or Unreal engine.
Bibliography
Asterix. 1983. Atari, inc, Atari, inc.
BARROS, Pablo, Ana TANEVSKA and Alessandra SCIUTTI. 2021. Learning from Learners: Adapting Reinforcement Learning Agents to be Competitive in a Card Game.
CARTA, Salvatore et al. 2021. ‘Multi-DQN: An ensemble of Deep Q-learning agents for stock market forecasting’. Expert Systems with Applications, 164, 113820.
IPPOLITO, Pier Paolo. 2019. ‘Feature Extraction Techniques’. Available at: https://towardsdatascience.com/feature-extraction-techniques-d619b56e31be. [Accessed Mar 4,].
MILLER, Brad L. and David E. GOLDBERG. 1995. ‘Genetic Algorithms, Tournament Selection, and the Effects of Noise’. Complex Syst., 9.
N. YANNAKAKIS, Georgios and Julians TOGELIUS. 2018. Artificial Intelligence and Games. Springer.
Figure List
Figure 1: Oates. Max. 2022. example of AI’s results between 0.6 and 0.9.
Figure 2: Oates. Max. 2022.example of AI’s results between 0.7 and 0.9.
Figure 3: Oates. Max. 2022. example of AI losing progression over time.
Figure 4: Oates. Max. 2022. example of scatter graph.
Figure 5: Oates. Max. 2022. example of line graph.