In this post I will be increasing the amount of elements in the example generation for the learning rate and discount factor based on previous research. In addition I will be experimenting with population and generation sizes, for this the AI will have 12 generations each with a population of 4. This is to find values with good results that I can use for fixed parameters. Finally, I will be polishing the code by adding comments and reducing code duplication where needed.
Parameter experimentation and training
As mentioned in earlier posts the a current problem with the AI is that it is using a design flaw in the game in order to get a high score. This is due to it finding the most efficient path too quickly and not taking risks. By adjusting the discount factor and learn rate parameters it seems to explore the environment more often and get a good score because of it. That being said it still happens too often, as well as that, when the AI reaches its last life it begins to drop in performance and does not do so well as when it had more lives.
My solution to this problem is to experiment with adding more values to the example generation for the discount factor and learn rate as this has had good results in the past when working with the Genetic Algorithm optimisation. As well as that, instead of training the AI for 3 generations I will instead run it for 12 to see if there are any improvements in its performance. The generation example can be seen below in fig 1.

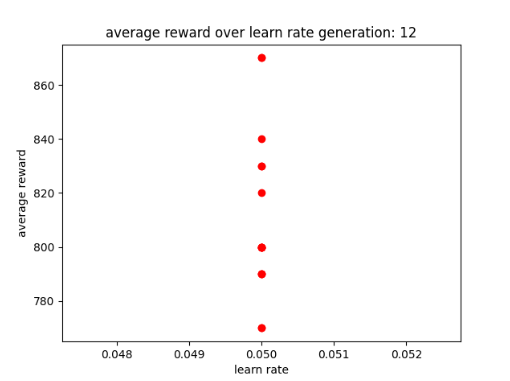
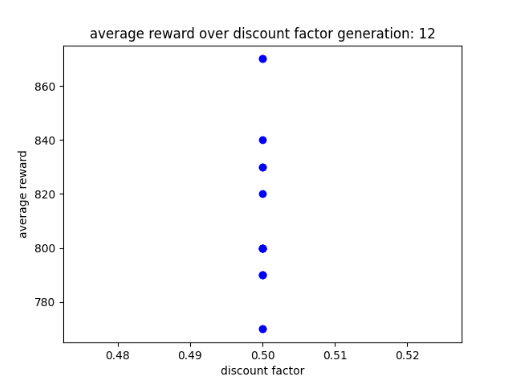
After Training the AI for 12 generations it seems to have reduced in terms of high scores as its highest score was 880 instead of 1200 or 1400. In addition, based on its results it seems to do well with a learn rate of 0.05 which is expected due to previous results. As for the discount factor it prefers a value of 0.5 for its planning horizon, this is also expected due to previous results. All of this is show between figs 2 to 4.

Looking at the AI’s performance when playing Asterix (1983) it seems that it switches between two behaviors, these being: explore a lot of the environment at the cost of a high score or be efficient and get a high score at the cost of exploration. Below are two videos that show its different performances.
As mentioned in earlier posts it is expected that when the AI is more explorative of its environment, it would be at the cost of its score. However, it has done better than expected since this AI is capable of achieving a score of 800 or 850 while still exploring the environment. This is good because in previous versions the AI could only reach a score between 400 to 650. While the solution has shown some promise, I think a better solution is required if I want the AI to have a better and more natural performance.
An observation I made during the AI’s training is that it is a lot slower when training without existing training data to use. To give an example, I noticed that it takes 1 hour for 5 generations to pass without training data, while it took 20 minutes for the AI to complete 5 generations when training with existing training data. This may be due to the AI having an idea of what to do in its environment when using training data. As for the AI without training data, it is starting from scratch and trying to find the most efficient path. I felt this was something to keep in mind when planning how long it will take for the AI to train and what I can achieve in the time frame.
Polish
Another problem I have been facing is to do with the AI using training data it has just created, as at the moment the user needs to tell the AI when to start using the training data. As I have found that it is very ineffective during experimentation as the AI may be training for 12 generations and the AI should start using the training data after the first generation but in current circumstances I would need to stop the training, set a parameter to true and then begin the training session again. In addition, I have noticed that the state of my code is not looking very professional and is in need of improvements.
My solution is to remove the Boolean parameter from the train_and_test function that tells the AI when to use training data, and replace it with code that simply checks if a file exists. This should mean that when the training data is saved after the first generation it will start using the existing data. For the system to know if a path exists or not I will use the os.path library. The code is shown below in fig 7.

Alongside this, to improve the quality of my code I have added comments so that it is clear what parts of the code do what and why. As well as that I have updated the code by moving large chunks of code to a separate function such as the lines of code that clear the lists used to store data for the CSV and graphs. This is to remove untidy code and to ensure that the lists can be cleared without need of duplicating code.
Further enquires
Looking at my AI’s functionality and how Reinforcement Learning (RL) relies on a minimum number of states for good performance, I wonder if a RL AI can play a card game with good performance due to its high amount of states and actions while still being dynamic for complex decision making (Mousavi et al. 2017). Upon researching existing papers it seems that RL can be used to play a card game, however some features like a greedy policy were mandatory in order for the AI to keep up. DQN did work well against both random and human opponents, however it was out performed by Proximal Policy Optimization (PPO) another type of reinforcement learning technique. (Barros et al, 2021).
If I were to try and use DQN to play a card game I would need to keep in mind how the AI would interact with the environment and the agent in it. Additionally, as the research shows, another technique performs better than DQN both with a human player and an opponent AI that uses random actions.
Reflection and conclusion
Upon reflecting on my work I can see that adjusting the parameters further does show some promise in getting the AI to explore its environment more often. However, as expected the AI did get a smaller score than when it is overfitting, but even then it was able to get a higher score than previous versions that explored their environments more often. That being said I am glad that the AI is improving.
However, while it is a success, the AI seems to switch between two types of behaviors when testing it in the environment. These two behaviours are: it will explore its environment more often or be efficient and use the design flaw and overfit. That being said, even when it does overfit it does explore the environment now and then.
In addition, polishing the code has made it look more professional, although in the end there was not much of the code’s architecture that I could change without affecting functionality. However, it is nice to see the improvement in the quality.
For my next post, ideally I would like to edit the environment’s code so that if the agent is standing still, it will lose points. This would be to ensure that it stops using the design flaw, however the environment script cannot be edited. Due to this, I will look into feature extraction as a way for the AI’s fitness function to try and time how long the agent is standing still. For example, if the agent is standing still for or longer than 2 seconds, do not save the data and try and give the AI a low reward through OpenAI Gym’s API.
The expected results can be achieved by using OpenAI Gym’s en.action_space function, where it will be used to check which action is being used in the current step (Brockman et al. 2016). Attached to this will be a counter which increases by one every time the action is nothing (noop). Now there are some potential problems such as OpenAI Gym’s API not working with DQN since it uses the stable baselines3 library, but it would be worth the experiment to see if it will work. In addition, the environment is created with OpenAI Gym which contains the function that states what kind of reward is given to the agent so manipulating the AI’s reward might be possible.
Bibliography
Asterix. 1983. Atari, inc, Atari, inc.
BARROS, Pablo, Ana TANEVSKA and Alessandra SCIUTTI. 2021. Learning from Learners: Adapting Reinforcement Learning Agents to be Competitive in a Card Game.
BROCKMAN, Greg et al. 2016. ‘OpenAI Gym’. CoRR, abs/1606.01540.
MOUSAVI, Seyed Sajad, Michael SCHUKAT, Enda HOWLEY and Patrick MANNION. 2017. Applying Q (Λ)-Learning in Deep Reinforcement Learning to Play Atari Games.
Figure list
Figure 1: Oates. Max. 2022. example generations with more parameters.
Figure 2: Oates. Max. 2022. AI after 12 generations.
Figure 3: Oates. Max. 2022. AI after 12 generations and a learn rate of 0.05.
Figure 4: Oates. Max. 2022. AI after 12 generations and a learn rate of 0.5.
Figure 5: Oates. Max. 2022. AI playing game with 12 generations part 1.
Figure 6: Oates. Max. 2022. AI playing game with 12 generations part 2.
Figure 7: Oates. Max. 2022. snippet of path checker code.
