In this post I will be implementing a simple system that will monitor the AI’s actions and adjust the reward accordingly, this is similar to feature extraction. The main goal of this is to stop the AI from standing still for too long and remove points if it does so. This is intended to train the AI and stop it from using the design flaw and get stuck in a local maxima. I will then be looking over the graphs from this and previous results and fixing the parameters to those set values. Finally, I will add more polish to the AI by replacing its step measuring system with a reward measuring system instead to ensue that the AI saves the best of its training data.
Introduction
After talking to one of my lecturers, he suggested that I find a way to include a system that stops the AI from performing specific behviours by adjusting its reward. For example, the most consistent problem with the AI is that it will stand still for too long at the corners of the environment, resulting in taking advantage of the game’s design flaw, this is because it believes that is the more efficient strategy. Looking over performance techniques for DQN, I have decided to use a feature extraction like system to monitor every action the agent performs. For instance, if it is standing still for too many steps in the environment it will lose points. This is intended to encourage the AI to keep moving in hope of it playing the game more naturally and not using the design flaw.
Feature extraction and reward adjustment
As mentioned in the introduction I aim to create a system that is similar to feature extraction. Feature extraction works by reducing the number of features in a given AI system by taking existing ones and replacing them with new features (Ippolito 2019). While I won’t be adjusting or creating features, I will be monitoring current features and telling the AI to use or ignore current techniques to ensure that it will not get stuck in a local maxima.
The system worked as I could access the current action the AI was performing, however the reward system did not work. Further inspection of my research revealed that the DQN example my research was using, was a custom DQN class and not Stable Baselines3’s DQN class, meaning the reward for the AI’s current state and action could not be adjusted (Sachin 2019). Going with the alternative part of the plan I did get feature extraction to work with the fitness function in a different way. I included a disqualifier variable that would increase by one if the agent was standing still for more than a specified amount of steps. If the individual had a smaller disqualifier than the other one then it would be picked. Additionally, when saving data it would check if the disqualifier value is smaller than 1200, as testing has shown that it is usually the smallest number. Below are screenshots of the code when being applied as well a flowchart of how it works.



Results of training for 3 generation
After 3 generations the AI was able to move around the environment without using the design flaw and play like a normal player. However, it did walk into obstacles at times causing it to lose the game, while at other times it could avoid the obstacles very well. The AI making the mistake of hitting obstacles that should be easy to avoid might be the result of a small amount of available training data. However, this problem will likely be taken care of by training the AI further and seeing what happens. Below is the video and graphs of the results.



Fixing parameters and results of training for 100 episodes
Based on collected training data I will fix the parameters to the set values to ensure that their performance is consistent. While training the AI, I intend it to still use its step checker and feature extraction algorithms so that it will only save its best performances. I will then be training the AI for 100 episodes to see if this will improve its performance. Below in fig 7 is the fixed parameters being used for the AI.
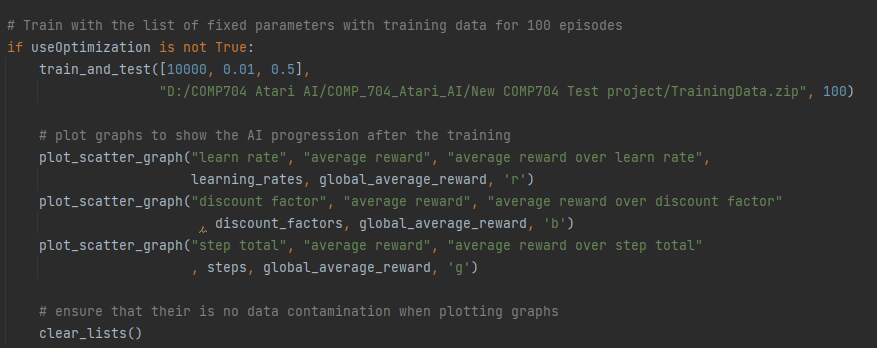
I chose these parameters because from previous results the AI works best with a learning rate between 0 and 0.5 and with a discount factor that is between 0.5 and 1. Looking further into the previous results from parameter optimisation I have chosen a step total of 10,000, a learning rate of 0.01 and a discount factor of 0.5. This has led to good results and was the reason it got a score of over 1000 in the past. However, this was at the risk of the AI using of the design flaw.
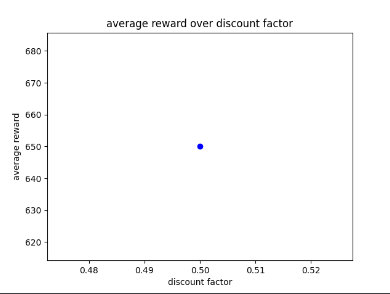
After training the AI for 100 episodes, it seems that the AI switches between two behaviours similar to previous versions of the AI, these are: explore at cost of the score and be efficient and get a good score at the cost of exploration. For example, The AI will explore the environment and get a good score between 400 to 650. After playing the environment a few times (mainly five) the AI will switch and begin to be very efficient and use the design flaw in the game. Additionally, the AI seems to perform best when there is not a lot of obstacles in the way and will be able to avoid and collect points with a small margin of error. Below in fig 8 is an example of the AI switching between behaviours mid playthrough.
After observing the AI’s training session and how frequent it was saving the data, it made me curious if the AI would work better without the feature extraction. I was wondering about this as training the AI whilst still standing still for quite some time made me question the effectiveness of the system. After training the AI for 100 episodes without the feature extraction it turns out the AI had performed a slightly worse as it was getting a score between 200 and 400. A video of its performance is shown below in fig 11.
An observation I made during the AI’s training is that it can only reach 650 when training with just episodes and not with GA optimisation. This was making me wonder if having changing parameters allows for the AI to get better results as its parameters are always changing to make sure that it performs better then last time. This would make sense as having static parameters that do not adjust to a game with random encounters would not allow for the kind of adaption that GA could provide.
Training after 3000 episodes
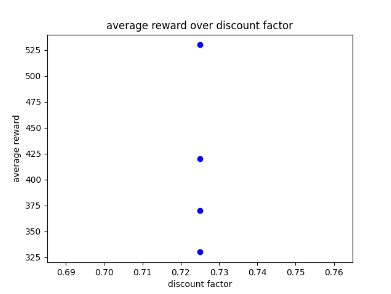
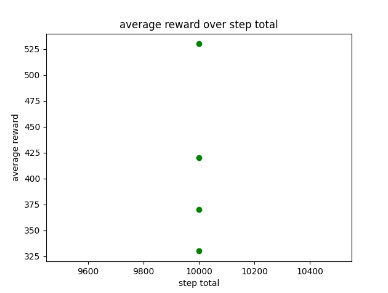
To test the AI’s performance further I decided to adjust the AI’s fixed discount factor parameters and train it for 3000 episodes to see if the extra training would help it improve and explore the environment more often. The discount factor parameter is now 0.752 as it has worked well in the past as well when getting the AI to explore its environment more often.
After training it would appear that the AI was still getting scores between 400 to 600 and has now resorted to staying still at one of the corners of the environment and only moving when needing to avoid obstacles, which only worked sometimes. Looking at the AI’s performance I believe it has gotten stuck on a local maxima even with the help of the feature extraction system trying to prevent this. This could be due to the randomness of the environment making it hard for the AI to adjust completely and find an efficient path. Below are the graphs showing off the results as well as the video of its performance.

Polish
As mentioned in a previous post I wanted the AI to measure rewards instead of steps to know when to save training data. While the AI was working well with the step solution, I noticed that the AI was getting very high scores but was not saving the training data due to the step total not being big enough. To ensure that the AI saves the right data I replaced the AI step measure system with a reward measurer, for more effective training.
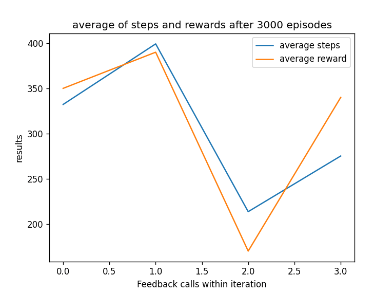
After training the AI for 3000 episodes, the AI would appear to have developed an interesting strategy where it will move around to collect as many points as possible and then stay still during its final life. This results in it getting a score between 200 and 750, which shows promise but is not consistent. In addition, the inconstancy is so common that the averaged graph of the collected training data does not show it achieving 750 as a score, this is shown below in fig 16.
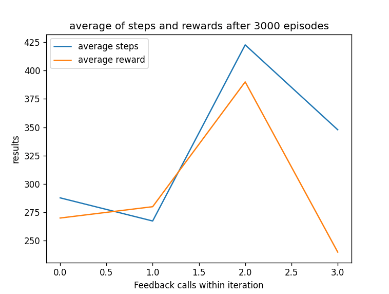
As you can see from the graph, it varies in scores and as mentioned previously the graph shows that the AI can get a higher score with a smaller step total, hence why the system exists.
The problem with the inconsistent score may be due to the AI recognising patterns in the games randomness and using those patterns to handle the random feature of the environment. Below is a video of the AI’s performance as well as a picture showing the AI achieving a score of 750 during training.
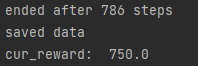
While this may not be the best solution, since this AI is able to achieve a score of 750 (which is higher than previous scores) then this solution does show promise to allow the AI to improve further, especially with its current training data.
Adjusting parameters
I then adjusted the learn rate parameter to 0.35 and the discount factor parameter to 1 to see if a larger discount factor and smaller learn rate would have any improvement while still keeping it in the radius that usually gives the best results. However, after training the AI for another 3000 episodes, the AI still performed the same tactics as before and stayed at one of the corners of the environment to get the best results. Additionally, the score still wasn’t concise, causing the graph to show results between 200 and 400. However, it was getting a score of 750 at a more consistent rate at first, but the score decreased over time to a score between 200 to 400. Below shows the set parameters, the times it saved the data and the graph of the results.
Further enquires
Looking at the AI, it only solves one goal which is to get the highest score possible. However, I am curious if it would be possible to give my AI multiple objectives in order to increase the agent’s chances of staying alive longer and thus getting a better score. For example, the AI could be given an objective such as keep moving when it stays still and when its moving around its objective would be to get the highest score possible. This might be possible, however it might mean readjusting how the system keeps track of objectives and how the rewards will be assigned.
Upon further research it seems that it is possible for this type of AI to exist but works best with more simple environments such as a simple game called “deep sea treasure”. In addition, for the scalar part of the AI instead of it measuring a single value, the system would need to measure a vector where each element represents the objective and pick the one with the highest value. While talking about objectives, the system can handle multiple objectives but they may need to be simple to avoid confusion. As for AI policies, the AI can work with the MLP policy but not the CNN policy (Nguyen et al. 2018). Overall the system shows promise and that it is possible to incorporate the system into my AI.
Reflection and conclusion
Upon reflection of my work, by adding the feature extraction system and improving the reward measuring system, the AI seems to be improving in its performance when saving and loading training data. This performance is improved further by adding fixed parameters based on the collected training data throughout the past weeks.
From looking at the results I am quite happy to see it improving, although it can be annoying that the AI can still occasionally make basic mistakes when in the environment and will still use the design flaw. Taking this further, the AI is still making mistakes, causing it to get lower scores than previous iterations, by this I mean the previous AI’s lowest score was 400 while now it can get 200. That being said, looking at the agent’s movement, the AI can recognise patterns in the environment’s randomness, allowing it to avoid obstacles and get rewards, thus allowing it to get a score as high as 750. Taking the training further and possibly changing the parameters slightly could allow for better performance. That being said, for the time being, having the AI’s parameters fixed at 10,000 for the step total, 0.5 as the learning rate and 0.752 as the discount factor will do very well for the time being. Although the reward may not remain 750 consistently at the start, it is able to score 750 throughout the entire game at an inconsistent rate, rather than eventually dropping over time.
In conclusion, with the improvements to the system and parameters, the AI is performing better than it has in the past, even if it is at the cost of the AI occasionally getting a lower score than before.
For future actions, since this is the last week of me working and experimenting on my AI, I will not be doing any more work on it. Instead, my next post will be a conclusion on everything I have learned on this course, the outcome of the AI and what I might do in the future if I want to take this AI further.
Bibliography
IPPOLITO, Pier Paolo. 2019. ‘Feature Extraction Techniques’. Available at: https://towardsdatascience.com/feature-extraction-techniques-d619b56e31be. [Accessed Mar 4,].
NGUYEN, Thanh Thi et al. 2018. ‘A Multi-Objective Deep Reinforcement Learning Framework’.
Sachin. 2019. ‘Reward Engineering for Classic Control Problems on OpenAI Gym |DQN |RL’. Available at: https://towardsdatascience.com/open-ai-gym-classic-control-problems-rl-dqn-reward-functions-16a1bc2b007. [Accessed Mar 02,].
Figure list
Figure 1: Oates. Max. 2022. flowchart of the feature extraction.
Figure 2: Oates. Max. 2022. screenshot of how action is measured.
Figure 3: Oates. Max. 2022. screenshot of consequences if standing too long.
Figure 4: Oates. Max. 2022. AI after training with feature extraction.
Figure 5: Oates. Max. 2022. learn rate after 3 generation.
Figure 6: Oates. Max. 2022. discount factor after 3 generation.
Figure 7: Oates. Max. 2022. step total after 3 generation.
Figure 8: Oates. Max. 2022. AI training with fixed parameters and not optimization.
Figure 9: Oates. Max. 2022. example of AI switching behaviours after 100 episodes.
Figure 10: Oates. Max. 2022. AI constantly getting a score of 650.
Figure 11: Oates. Max. 2022. screenshot of AI performance without feature extraction.
Figure 12: Oates. Max. 2022. discount factor results after 3000 episodes.
Figure 13: Oates. Max. 2022. learn rate results after 3000 episodes.
Figure 14: Oates. Max. 2022. step total results after 3000 episodes.
Figure 15: Oates. Max. 2022. video of AI after 3000 episodes.
Figure 16: Oates. Max. 2022. graph of AI’s performance.
Figure 17: Oates. Max. 2022. AI with improved reward measuring system.
Figure 18: Oates. Max. 2022. AI achieving a score of 750.
Figure 19: Oates. Max. 2022. new parameter data.
Figure 20: Oates. Max. 2022. AI saving data.
Figure 21: Oates. Max. 2022. results from training with new parameters.
