In this post I will be experimenting with discount factor parameters between 0.5 and 1. As well as that I will be trying the AI in a different environment to see if it can run and train with little to no changes. Additionally, I will changing the learn rate and discount factor based on pervious experimentation to see if that improves its performance. By doing this I should be able to find good parameters for the AI to use and get it to play the game in a more natural manner.
Training
In this experiment I was changing the generation example’s discount factor so that it was between 0.5 to 1. This is to see if this would affect the AI’s planning horizon and thus hopefully move around the environment more often and prevent from overfitting.

During the training I remembered that chances of the discount factor parameter being mutated in the genome are up to random chance. This means generation examples might be the only ones used. In addition, random mutation affected the experiment due to it mutating the discount factor from a value between 0.5 – 1 to 0.2, below the intended parameter scale. An example of this happening is shown below in fig 2.
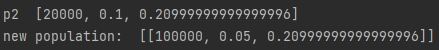
Looking at the graph the AI performed quite well with 0.2 as its parameter which is expected as a smaller discount factor parameter means a more efficient solution which usually results in a very big score. That being said, the second generation it got rewards between 450 and 600 while the first generation got a score of 1200 which was before the mutation occurred. This means by chance, the AI was able to get a score of 1200 once with a discount factor between 0.5 and 1.


Running in the environment
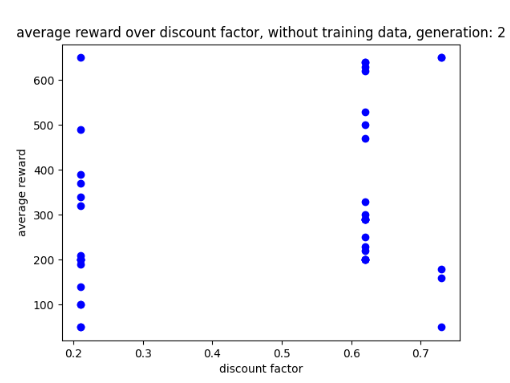
Looking at the AI interact with the environment with a higher discount factor shows promise as it moves around the environment and does not exploit the design flaw. However, this is at the cost of big scores as its biggest score was 450.
Further training with data set
In this experiment I began training the AI further with an existing data set from previous training. The AI was trained for another 3 generations (6 generations in total).
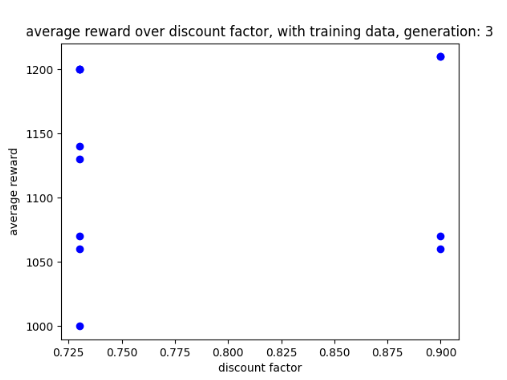
During the training with the data set it almost immediately began using the design flaw to get a score of 1200. Additionally, I have noticed that when it has one life left it performs less well compared to when it had three and two lives left.
Looking at the graph it appears that doing well with a discount factor of 0.2 in previous generations has not affected the AI when performing as its performance switches between 0.5 and 1. Because of this I think it might not be a problem if the mutation does affect the range of the generation examples.

Despite all that, when playing the game in human render mode (so that we can see play at normal speed) it appeared to be behaving the same way it did with only a data set of 3 generations.
Looking at its performance its making me wonder if the discount factor is having a big impact on its performance to such a point that having training where it uses the design flaw does not have much impact. This would make sense since the discount factor affects the AI’s planning horizon (III and Singh 2020).
Running AI with 9 generations of training data
After running the AI with 9 generations worth of data and a discount factor ranging between 0.7 and 0.9, the AI did still take advantage of the design flaw. However, there were some moments where it would move from the top of the level (the design flaw) and move around the environment. This Allowed it to get a score of 1250, 50 points higher than when it just used the design flaw.
Testing the AI in a different environment
Looking back at one of my previous further enquires, due to having some time I decided to test my AI in a different Atari environment and see if the AI can play a different game without needing any changes to the code. My choice of environment is the Atari game Assault (Brockman, 2020).
While the AI is playing Assault, with its current generation example parameters, like Asterix(1983) it is possibly that the AI is being too efficient and staying in one part of the environment. I believe this to be the case due to it staying still in one part of the environment. This is shown in the video below in fig 9.
During its training the AI did work and showed promise, however there were events where an error would occur causing the AI to stop training all together. This is shown below in fig 10.

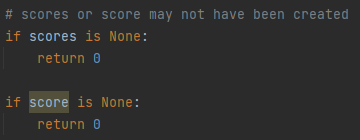
This was happening due to the AI returning a value of type None thus preventing the SUM function to work. The possible cause for the AI returning 0 was because it was getting a score of 0 while training. Though it was annoying that it was not working, this experiment has shown that it is possible for the AI to return None. So I have added some code to check that score or the list of scores is None. A picture of the code is shown below in fig 11.
Adjusting learn rate and discount factor parameters
The final experiment that I’m doing in this post is change the learning rate and discount factor parameters based on previous training data to so if the AI can improve on performance without overfitting.
Looking at previous training data, the AI works best with learn rate parameters between 0 and 0.5 and discount parameters between 0.5 and 1. based on this the example generation will be given parameters based on this. The example parameters are shown below in fig 12.

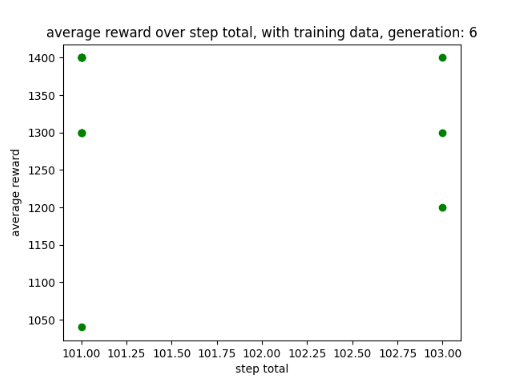
While training the AI for 6 generation I noticed it was able to achieve a score of 1400, how this was at the expense of it overfitting. That being said in order for it to achieve this it had to moved around the environment as pervious training has shown that just staying at the top of the level results in a score of 1200. A screenshot of training is shown below in fig 13 and a graph showing its score in fig 14.


Once it had finished training the AI was able to get a score of 1400 when playing Asterix(1983) at normal speed, this is shown in the graph below in fig 15. However, it did overfit for most of the run through, that being said, it did on occasions move around the environment to get points, which was expected as mentioned earlier. Below in fig 16 is a video of its performance.
Further enquires
While training the AI I had noticed that stopping the training, adjusting the parameters and the training again was a bit tedious. As a fix for this I was wondering it would be possibly to have the example generation parameters change based on the smallest and biggest values the user gets. This idea could be useful if the user wants to change the parameters when trying to narrow in on a good set of example parameters, however it could be vexing when trying experimenting with random ranges in parameter sizes and the system begins to close in on a potential fix when that was not the intention.
Reflection and conclusion
Reflecting on my work I can see that by adjusting the parameters for the learn rate and discount total has improved the AI performance. However despite the changes to ensure it stops using the discount factor, it seams that the AI will still overfit and use the design flaw in the game.
In addition, I wanted to se if the AI would be able to play a different game and though it was not successful it has revealed that its possible for the AI to return a type of None when returning its fitness. Because of this measures have been put in place to ensure that None is not returned.
Despite these problems and feeling vexed about them, the AI has been able to improve, now being able to gain a score of 1400 by using the design flaw and moving around the environment optionally. Additionally, due to the randomness of the game it would be hard to predict what move to make next, which might be empowering its decision to stay still at the top of the level.
In conclusion, the AI has improved by adjusting its parameters, however has mentioned in the previous post, it might be very difficult for the AI to get a large score without using the exploit. Because of this it may be best to look at other alternatives.
For my next action I will continue to experiment with the learn rate and discount factor parameters, such as increase the number of elements in the generation example that the AI uses when creating a generation. In addition, I will begin commenting and polishing the code to make sure it looks more professional.
Bibliography
Asterix. 1983. Atari, inc, Atari, inc.
Brockman, G. et al., 2016. Openai gym. arXiv preprint arXiv:1606.01540.
III, Hal Daumé and Aarti SINGH. (eds.) 2020. Discount Factor as a Regularizer in Reinforcement Learning. PMLR.
Figure list
Figure 1: Oates. 2022. generation example for discount factor parameter.
Figure 2: Oates. 2022. mutation causing smaller discount factor.
Figure 3: Oates. 2022. generation 1.
Figure 4: Oates. 2022. generation 2.
Figure 5: Oates. 2022. generation 3.
Figure 6: Oates. 2022. AI playing game with low score.
Figure 7: Oates. 2022. example of AI switching between 0.7 and 0.9 discount factor.
Figure 8: Oates. 2022. AI taking advantage of design flaw.
Figure 9: Oates. 2022. AI training to play Assault.
Figure 10: Oates. 2022. example of None error.
Figure 11: Oates. 2022. picture of code used to check None is not being returned.
Figure 12: Oates. 2022. altered example generation parameters.
Figure 13: Oates. 2022. AI achieving a score of 1400.
Figure 14: Oates. 2022. graphs showing score of 1400.
Figure 15: Oates. 2022. AI after 6 generations.
Figure 16: Oates. 2022. video of AI getting a score of 1400.
