For my first journal entry I will be explaining the game my AI will be playing and the algorithm picked for its learning capabilities.
The Concept
For this project I will be creating an AI that will learn to play Snake (1976) using Q-learning, a reinforcement learning method, to learn and improve over time via trail and error. When the snake moves around it will receive a reward of 0, while when the snake hits itself it will lose a point (-1) and when it hits a fruit it will get a point of 1.
The game
The AI’s environment will be Snake (1976) as it is a simple game to play with some challenges such as the snake getting bigger over time and the fruit spawning in random positions. Because of this I believe it will fit for my scope of 5 weeks. A picture of Snake (1976) is shown below in fig 1.

However, to ensure that the AI can learn from it mistakes I want to see if I can give the fruit a set position so that the fruit will spawn in the same position each game unless it’s going to spawn where the snake currently resides in which case the position will be random. In addition, while Snake (1976) is arguably endless which could be problematic, so to ensure their is a reach able goal, all the AI needs to do is collect 10 pieces of fruit and the game will be over.
The algorithm
The algorithm that I will be using is Q-learning, a reinforcement algorithm that is off policy and uses Temporal Difference (TD) control. Because it is a reinforcement algorithm it will be using trial and error to learn and won’t rely on an existing model or data to determine its decisions. This would save time as I won’t need to collect data from users to make the AI work during the first attempts at training, however it will mean that’s the first bit of training will mainly be it moving in random directions and losing the game (S. Sutton and G. Barto 2018).
Q learning uses rewards to make decisions on which action to preform and since it incorporates the greedy policy it will pick the reward with the highest value. However, to prevent it from making mistakes such as ignoring paths that might have a higher reward 10% of the time instead of 100% of the time, the algorithm will use a random event to decide if it should explore (pick an action at random) or exploit its environment (use Q learning algorithm and sampled action/state). The random event will be based on the epsilon value which is a part of the greedy policy. At the beginning of training epsilon will be set to 1 meaning it should explore the environment 100% of the time, however over time the number should go down to increase the chances of it picking exploit rather than explore (Lee 2019).
As mentioned earlier the AI uses rewards, received from doing good or bad actions, this is used in the Q learning equation to ensure that a higher quality value is calculated and stores in the q table so that is will likely be picked again in later steps. The reward value will increase or decrease during the training and will be set back to zero at the start of each training session (S. Sutton and G. Barto 2018). A diagram of the Q learning equation is shown below in fig 2.

Q-learning uses a table to store its actions and states, this stores the data it has gain through its learning and will use when making decisions on which action to pick (N. Yannakakis and Togelius 2018). For the AI to play snake it will have at least 4 actions, those being: up, down, left and right. These are based on the values assigned to its state, which in this case will be the position it’s currently in, then it will pick the action with the highest value. An example of what the table might look like is shown below in fig 3.
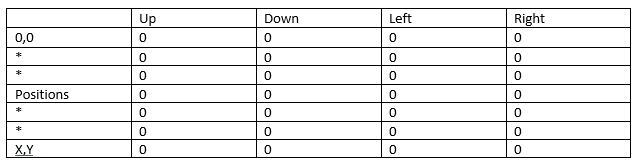
In addition, other actions could be added on if need be such as an action for fruit which should have a very reward value and a death action which should have 0 or a very low reward value in most columns of the table
A limitation of Q learning is to do with the table as depending on the chosen action and state the number of row and columns could be become incredibly large. Due to this the memory and computational requirements could become very high and thus increasing the amount of time per decision, affecting the quality of the results (N. Yannakakis and Togelius 2018).
There are two ways to avoid this the first is by being careful about the choice of action and state to keep it as small as possible. The other option is to use neuroevolution due to it being able to sensibly pick actions and states for a system while still remain companionly friendly (N. Yannakakis and Togelius 2018).
Since I only have 5 weeks I aim to go with the former as mentioned earlier when it comes to actions there are only 4 to pick from. As for states they will be the positions of the grid, but each axis should be stored as a whole number. In addition, the grid making up the environment will be 15 x 15 meaning in total there will be 225 states, which is small compared to the possible billions of states that a more complex game could have in terms of positions.
Potential problems
While I have been careful on what game and AI solution to pick, I am nervous about how unforeseen bug and problems could get in the way and affect development. For example, a potential problem could be compatibility between the AI and the environment resulting in errors that the AI can’t handle and removing time required for development.
However, if these problems do occur, then I would have to adjust my development scope and features to meet the new availability I have to build, train and polish the AI.
Training environment
Since I only have 5 weeks I will be using open AI Gym to create the training environment. While the current Open AI Gym doesn’t have Snake there is a plugin that I found which allows it to have that environment (Grant and Rishaug 2021).
Research and Development timeline
As mentioned earlier I have 5 weeks to research, develop and train the AI, I will aim this week to solely research for other the AI and it’s environment. I will then use the next 2 weeks developing the AI to ensure that it works properly. The last two weeks will be spent polishing and training the AI to ensure that it can collect 10 pieces of fruit. In fig 4 you can see a Gantt chart of my research plan and how I will spend these 5 weeks.

Further enquires
During the training session I need to keep track of the AI’s reward and its parameters to ensure I get good results and training data, however this will take some time to find out the correct set of parameters to get the best results. Consider how I have a shot scope I’m curious if a simple Q-learning system or linear regression system could be used to make a prediction on what kind of score the AI will get based on it’s current parameters. For example, if a multi-variable linear regression system used collected training data and using these results I could compare what the score the AI got, compare it to the predicted score and then adjust the parameters to see if the AI could improve to reach the predicted results (Tsoukalas and Fragiadakis 2016).
Of course I would need to make sure the predictions are correct which would means the linear regression would requires lots of training data generated by the AI to ensure that it matches. But having the score something to compare to would allow for accurate improvements rather then lots experimentation with little results.
Reflection and conclusion
Reflecting on my research, I am quite excited to use Q-learning and build one from scratch as it will allow me to gain more experience as an AI programmer. By building this AI from scratch I will have a great portfolio piece and while time is short the equation required for the AI is quite simple and shouldn’t be too hard to implement. That being said one of the complication I feel I will face is a seeing if positions can work as the AI’s states, however that will be figured out over time. From here I aim to being development on the Q-learning AI and at least have the structure of the AI set up and ready for functionality.
Through out my journal I will be reflecting on my work with Gibb’s reflective cycle, which contains 5 states: Description, Feelings, Evaluation, Conclusion and Action (Ashby 2006).
Bibliography
ASHBY, Carmel. 2006. ‘Models for reflective practice’. Practice Nurse : The Journal for Nurses in General Practice, 32(10), 28.
GRANT, Satchel and Joakim RISHAUG. 2021. ‘Gym-Snake’. Available at: https://github.com/grantsrb/Gym-Snake. [Accessed 26/1/22].
LEE, Dan. 2019. ‘Reinforcement Learning, Part 6: TD(Λ) & Q-Learning’. Available at: https://medium.com/ai%C2%B3-theory-practice-business/reinforcement-learning-part-6-td-%CE%BB-q-learning-99cdfdf4e76a. [Accessed 24/1/22].
N. YANNAKAKIS, Georgios and Julians TOGELIUS. 2018. Artificial Intelligence and Games. Springer.
S. SUTTON, Richard and Andrew G. BARTO. 2018. Reinforcement Learning an Introduction. (Second edn). United States of America: Westchester Publishing Services.
Snake. 1976. Gremlin Interactive, Gremlin Interactive.
TSOUKALAS, V. D. and N. G. FRAGIADAKIS. 2016. ‘Prediction of occupational risk in the shipbuilding industry using multivariable linear regression and genetic algorithm analysis’. Safety Science, 83, 12-22.
Figure List
Figure 1: Unknown maker. ca. 2019. No title [photo]. V&A [online]. Available at: https://community.phones.nokia.com/discussion/44549/snake-through-the-ages.
Figure 2: ADL. ca. 2018. No title [diagram]. V&A [online]. Available at: https://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/amp/.
Figure 3: Max Oates. 2022. example of AI’s states and actions table.
Figure 4: Max Oates. 2022. Table of development timeline.